Welcome to Zhihang Xu(徐志航)’s Text-To-Speech Demo Page
CONTACT me xuzhihang2007#163.com or zhihangxu#microsoft.com
-
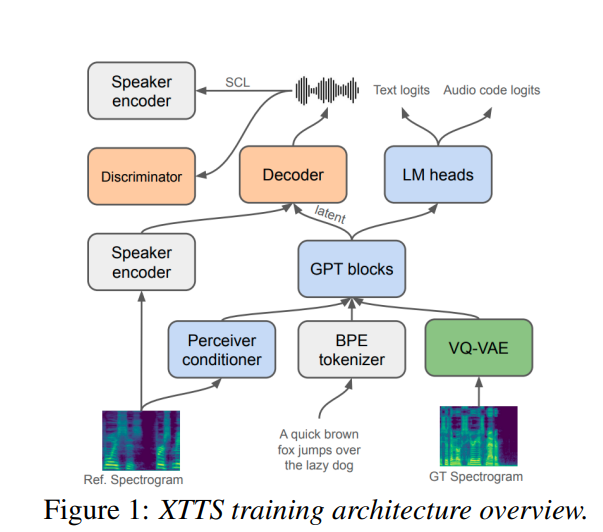
Decoder only AR speech synthesis
- basic structure just like xtts
- 50ms based group residual VQ pretrained on large amount of foundation data
- gpt like transfomer model with parallel code prediction
- xtts like preceiver-resampler with code emb as input
- training strategy: flash attention / bfloat16 / gradient accumulate
-
demo page
-
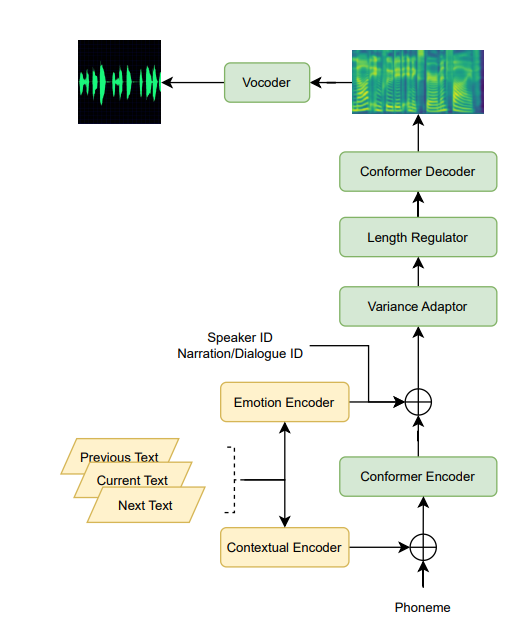
MuLanTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2023, Zhihang Xu, Shaofei Zhang, Xi Wang, Jiajun Zhang, Wenning Wei, Lei He, Sheng Zhao
- In this paper, we present MuLanTTS, the Microsoft end-toend neural text-to-speech (TTS) system designed for the Blizzard Challenge 2023.
- MuLanTTS achieves mean scores of quality assessment 4.3 and 4.5 in the respective tasks, statistically comparable with natural speech while keeping good similarity according to similarity assessment. The excellent quality and similarity in this year’s new and dense statistical evaluation show the effectiveness of our proposed system in both tasks.
- Model detail highlight:
- leverage of pretrained text emb from NLP task
- paragraph training with contextual sentences.
-
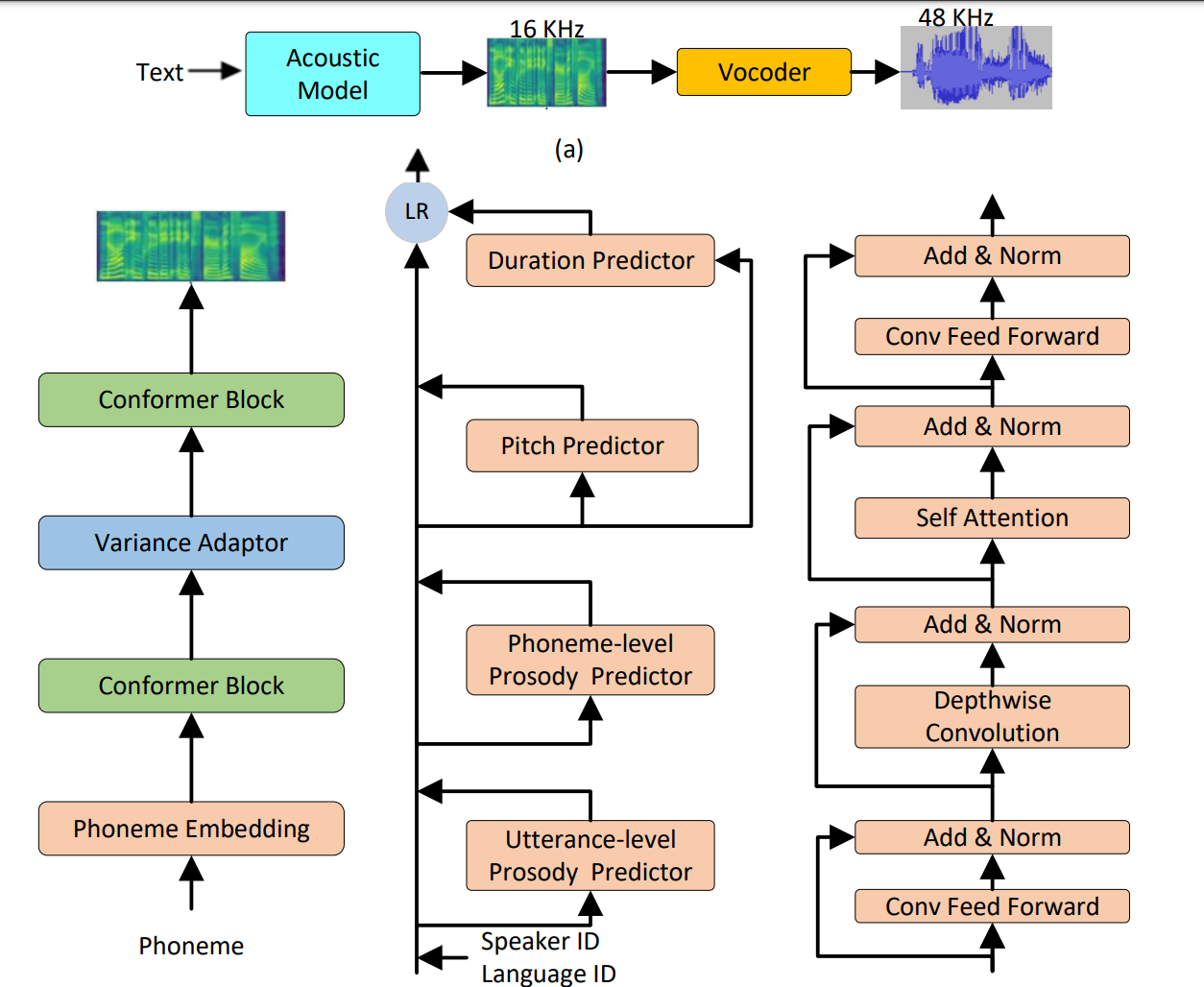
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021, Yanqing Liu, Zhihang Xu, Gang Wang, Kuan Chen, Bohan Li, Xu Tan, Jinzhu Li, Lei He, Sheng Zhao
- This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. (link: https://arxiv.org/abs/2110.12612)
- DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which won the 1st place in MOS/SMOS/SUS intelligibility in SH1 task out of 13 teams.
- Model detail highlight:
- we directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate
- The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness.
-
demo page
-
Multistyle Mixlingual Xiaoxiao v4 model building
- Model detail highlight:
- Encoder and decoder pretraining.
- Style disentanglement on mutiple style imbalanced dataset.
- English mixlingual TTS backend solution.
- Full distillation for compress model size, RTF and latency.
- Multiple Band 24k hifiNet vocoder.
-
demo page
- Model detail highlight:
-
Full distillation method and multiple AM for Uni-TTS v4.
- Motivation: reduce model size, save memory, flexible acoustic model combination, provide different compression ratio for different purpose.
- Model detail highlight:
- model structure compression and dimension compression.
- Change conformer feed forward layer into separable CNN and reload teacher network.
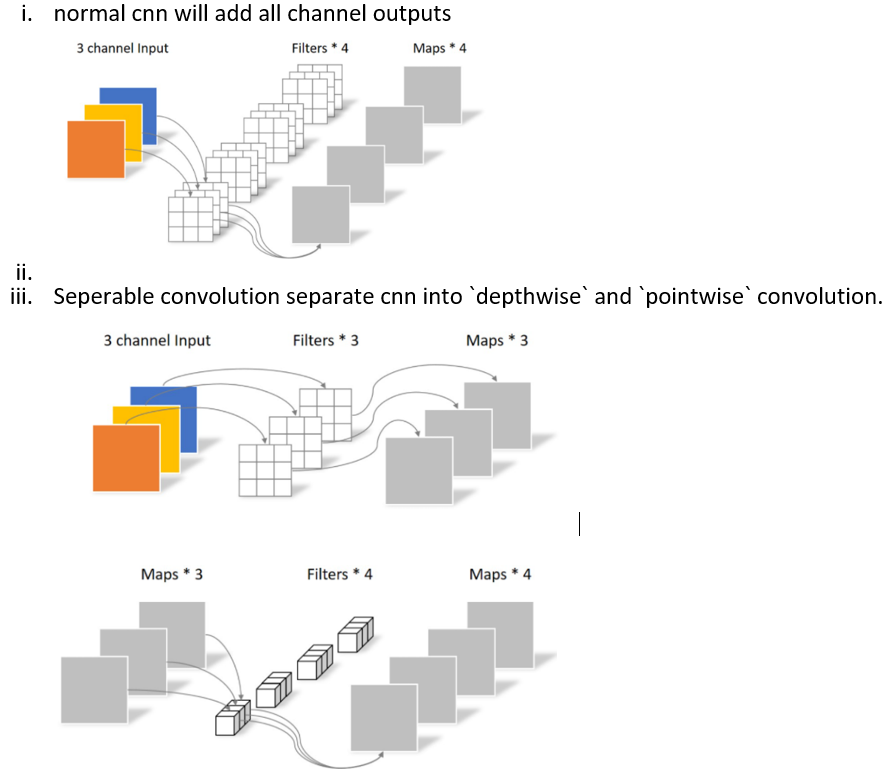
- Auxiliary encoder hidden constraint and attention constraint.
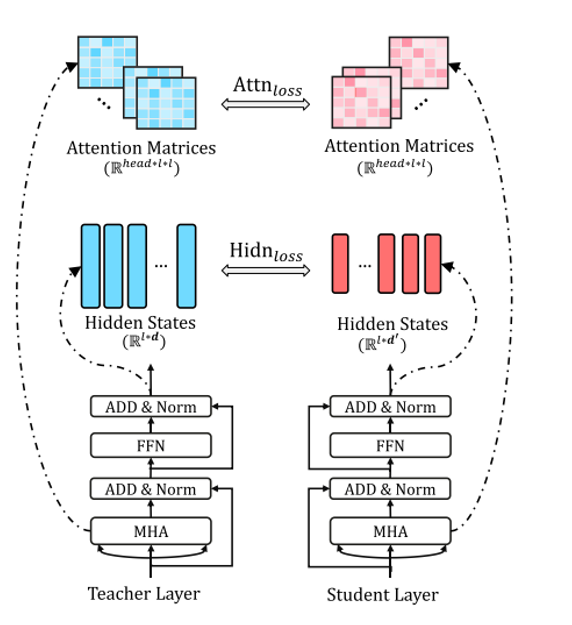 ***
***
-
Phone level speaker embedding based speech synthesis adaption method under small data, Zhihang Xu, Bo Chen, Kai Yu
- In this paper, we proposed a novel phone leveled speaker embedding for speaker adaptation, especially VOICE CLONING task
- we can achieve best similarity compared with other embeddings, making adaptation training faster and stable.
- paper link: http://cjc.ict.ac.cn/online/onlinepaper/xzh-2022426184330.pdf
-
demo page
-
PrEtrained Text Speech(PETS) for prosody model
- we propsed a new way to build prosody model inspired from (Automatic Prosody Annotation with Pre-Trained Text-Speech Model, Tencent AI Lab, 2Peking University)
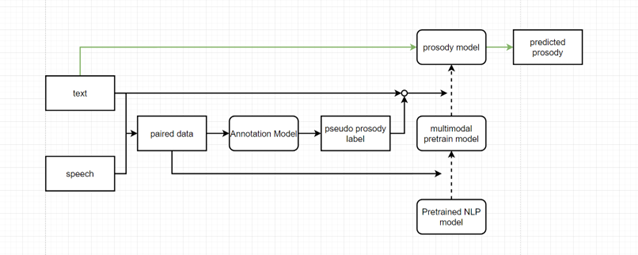
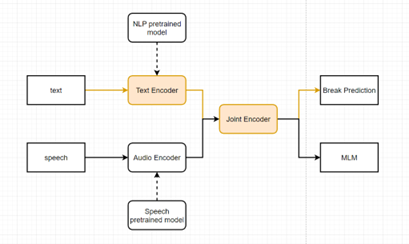
- step 1. Data preparation:
- Using Annotation model to extract pseudo prosody label from paired (text, speech) data from our zhcn ttsdata.
- Handling the pseudo labels into our prosody break (br0-br4)
- step 2. Speech-text joint pretraining
- Using a pretraining framework like SLAM
- Traditional unsupervised task: MLM, constrastive loss
- SLAM will restore some pretrained NLP model roberta Ernine3.0 ELECTRA and some pretrained speech models like wav2vec2, Hubert, w2v-BERT
- Prosody prediction task will be designed using CTC based model to get preudo label
- step 3 Text-only prosody model refinement
- step 4 retrain AM with new prosody model
- step 1. Data preparation:
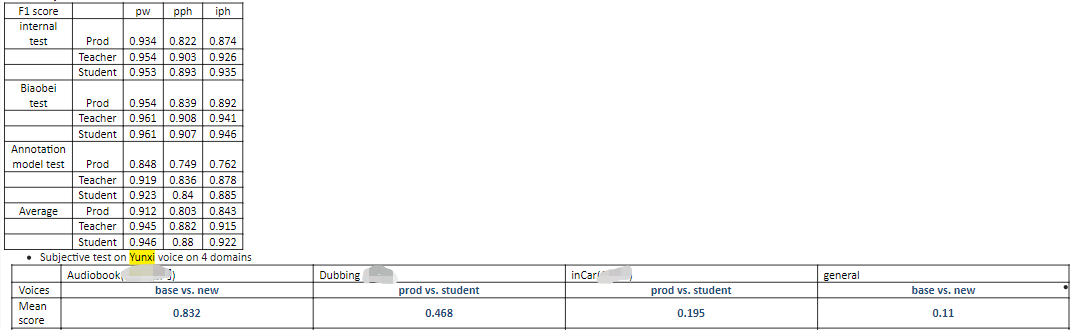
- score card
-
[demo page] not ready
- we propsed a new way to build prosody model inspired from (Automatic Prosody Annotation with Pre-Trained Text-Speech Model, Tencent AI Lab, 2Peking University)
-
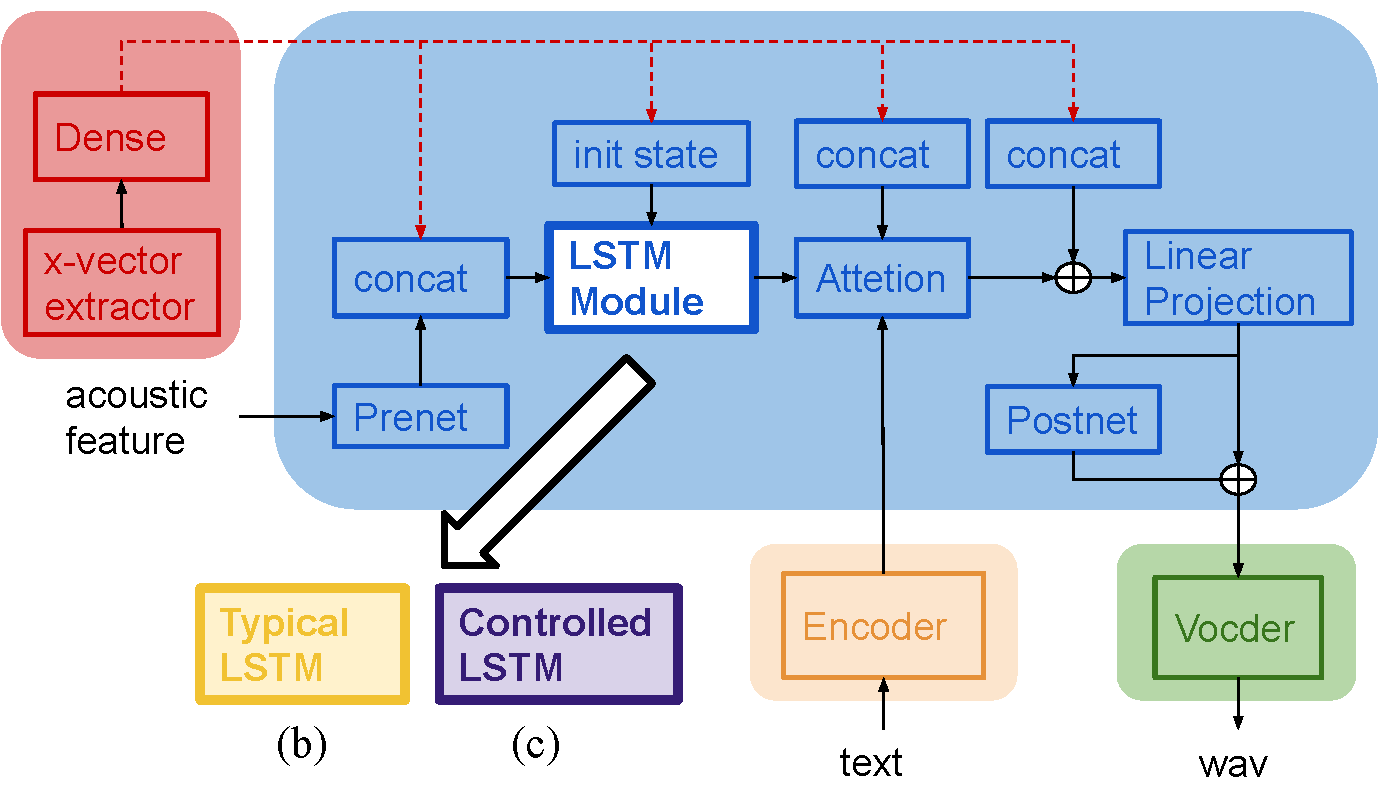
UNSUPERVISED TTS SPEAKER ADAPTATION USING X-VECTOR CONTROLLED PARAMETERS, Zhihang Xu, Bo Chen, Kai Yu (rejected by Interspeech2020)
- In this paper, we proposed a novel unsupervised adaptation method, which makes the TTS model parameters controlled by xvector.
- The experiments result shows that this can improve the similarity and naturalness especially on dirty unseen speakers.
- model introduction: we followed the Tacotron2 framework, and make the decoder LSTM to controlled by scaling the shifting vectors, whici are trained from xvector with the whole TTS model.
-
demo page
-
Bo Chen, Kuan Chen , Zhijun Liu, Zhihang Xu, Songze Wu, Chenpeng Du, Muyang Li, Sijun Li, Kai Yu. “SJTU Entry in Blizzard Challenge 2019”paper
- In this chanllenge, to build a high speech quality with rich speaking styles, the TTS system is consist of “Front-end Text processor”,”Back-end Spectrum mode”,”Wavenet Vocoder” and “Bandwith Extender”.
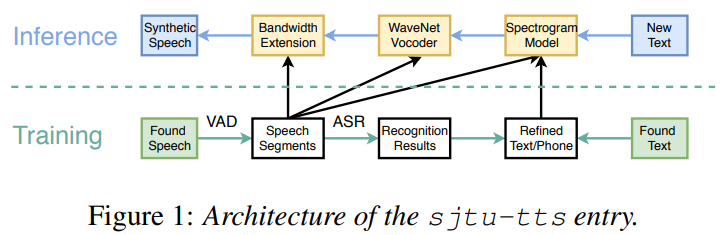
- Here we give some examples of speeches synthesized using test texts in difference types: 1 minute long talk show texts/ short spoken texts / Chinese poems
-
demo page
-
TCVAE based Nonparallel Voice Conversion demo
-
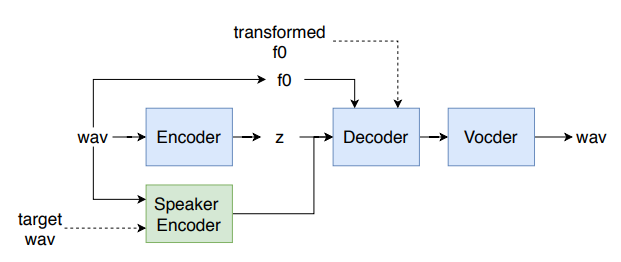
- In this research, we apply TCVAE into nonparallel voice conversion on Chinese corpus.
- also we compare the different usual acoustic feature for this task, shows the importance f0 feature for voice conversion task on Chinese corpus.
- Here we show the voice conversion among Chinese speakers and English speakers.
-
demo page
-
F0 controlled Tacotron speech synthesis demo
- model introduction
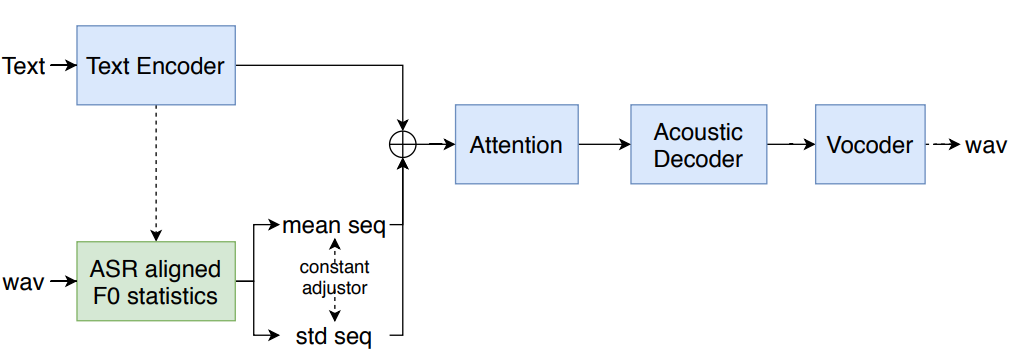
- We use the F0 statistic feature(mean and std) of a small audio segment (from phone asr force alignment) to control the speech speaking style
- For inference, we use the text to predict the F0 statistic feature
- We can see the result that the speeches is controlled by F0 mean and std obviously.
-
mean: demo page
-
std: demo page
- model introduction